
- Tại sao chọn LM Studio để chạy AI cục bộ?
- Yêu cầu phần cứng và chuẩn bị trước khi cài đặt
- Cách tải và cài đặt LM Studio trên Windows, macOS và Linux
- Cài đặt trên Windows
- Cài đặt trên Linux (Ubuntu)
- Cách bật tăng tốc GPU AMD trong LM Studio
- Cách tải và chạy mô hình ngôn ngữ trong LM Studio
- Nếu dùng để hỗ trợ code, nên chọn mô hình nào?
- Cách bật server API nội bộ để tích hợp với công cụ lập trình
- Bật server trong giao diện đồ họa
- Tích hợp với Python hoặc ứng dụng bên thứ ba
- Mẹo tối ưu hiệu năng khi chạy LM Studio với GPU AMD
- Xử lý sự cố thường gặp khi chạy LM Studio trên AMD
- LM Studio không nhận diện được GPU AMD
- Mô hình load thành công nhưng chạy chậm như CPU
- Lỗi HSA_OVERRIDE_GFX_VERSION trên card không được hỗ trợ
- Kết luận: AI cục bộ trên AMD đã sẵn sàng cho người dùng phổ thông
Chạy mô hình ngôn ngữ lớn (LLM) ngay trên máy tính của bạn mà không cần kết nối internet hay trả phí API. LM Studio là công cụ miễn phí, giao diện trực quan, và đặc biệt tương thích tốt với card đồ họa AMD qua nền tảng ROCm và Vulkan. Bài viết này sẽ dẫn bạn từng bước tải phần mềm, cấu hình GPU, tải mô hình và bật server API nội bộ để tích hợp vào các công cụ lập trình.
Tại sao chọn LM Studio để chạy AI cục bộ?
LM Studio biến việc chạy LLM từ một thao tác dòng lệnh phức tạp thành trải nghiệm kéo-thả đơn giản. Phần mềm tích hợp sẵn trình duyệt mô hình từ Hugging Face, cho phép bạn tìm kiếm, tải về và chạy thử nghiệm ngay lập tức mà không cần cài đặt thêm Python hay biên dịch mã nguồn. Điểm mạnh nổi bật là khả năng tương thích đa nền tảng: macOS (Apple Silicon), Windows, Linux — và đặc biệt hỗ trợ tăng tốc GPU AMD thông qua Vulkan hoặc ROCm, giúp tận dụng tối đa phần cứng thay vì chạy chậm chạp trên CPU.
Một tính năng quan trọng khác là server API tương thích OpenAI chạy ngay trên máy local. Điều này có nghĩa là bạn có thể kết nối LM Studio với các công cụ như Continue.dev, Claude Code, hay script Python của riêng mình — tất cả đều trỏ về http://localhost:1234 thay vì gọi đến dịch vụ đám mây. Dữ liệu không bao giờ rời khỏi máy tính, đảm bảo quyền riêng tư tuyệt đối cho mã nguồn và tài liệu nội bộ.
Yêu cầu phần cứng và chuẩn bị trước khi cài đặt
Trước khi bắt đầu, hãy kiểm tra cấu hình máy tính của bạn. LM Studio không đòi hỏi quá cao, nhưng để trải nghiệm mượt mà với các mô hình 7B–13B tham số, bạn nên có ít nhất:
- CPU: Bộ xử lý đa nhân từ 4 nhân trở lên (Intel thế hệ 10+ hoặc AMD Ryzen 3000+).
- RAM: Tối thiểu 16 GB, khuyến nghị 32 GB để chạy mô hình lớn hơn hoặc đa nhiệm.
- GPU AMD: Card đồ họa Radeon RX 6000 series (RDNA2) trở lên, RX 7000 series (RDNA3) được hỗ trợ tốt nhất. VRAM càng nhiều càng tốt — 8 GB là mức tối thiểu cho mô hình 7B, 16 GB cho 13B, và 24 GB trở lên cho 30B+.
- Ổ cứng: Mô hình GGUF thường nặng 4–8 GB, nên cần ít nhất 20 GB dung lượng trống.
- Hệ điều hành: Windows 10/11, macOS 12+, hoặc Linux (Ubuntu 22.04/24.04 được khuyến nghị cho ROCm).
Nếu bạn dùng card AMD không nằm trong danh sách hỗ trợ chính thức của ROCm (ví dụ RX 6600, RX 6700 không XT), LM Studio vẫn có thể hoạt động qua backend Vulkan hoặc bằng cách ghi đè biến môi trường HSA_OVERRIDE_GFX_VERSION. Tuy nhiên, hiệu năng có thể không ổn định bằng card được hỗ trợ chính thức.
Cách tải và cài đặt LM Studio trên Windows, macOS và Linux
Quá trình cài đặt LM Studio rất trực quan. Truy cập trang chủ lmstudio.ai và chọn phiên bản phù hợp với hệ điều hành. Hiện tại LM Studio cung cấp bản cài đặt .exe cho Windows, .dmg cho macOS, và AppImage cho Linux.
Cài đặt trên Windows
Tải file cài đặt, chạy và làm theo hướng dẫn. Sau khi hoàn tất, khởi động LM Studio. Nếu bạn muốn dùng GPU AMD để tăng tốc, đảm bảo driver AMD Adrenalin mới nhất đã được cài đặt. LM Studio trên Windows sử dụng backend Vulkan hoặc DirectML cho card AMD, không cần cài thêm ROCm.
Cài đặt trên Linux (Ubuntu)
Với Linux, phương án phổ biến nhất là dùng file AppImage:
chmod +x LM_Studio-*.AppImage
./LM_Studio-*.AppImageNếu bạn muốn tận dụng tối đa GPU AMD qua ROCm, cần cài đặt ROCm trước. Trên Ubuntu 22.04/24.04, chạy các lệnh sau:
wget https://repo.radeon.com/amdgpu-install/latest/ubuntu/jammy/amdgpu-install_*.deb
sudo apt install ./amdgpu-install_*.deb
sudo amdgpu-install --usecase=rocm
sudo usermod -aG render,video $USERSau khi cài đặt, khởi động lại máy và kiểm tra bằng lệnh rocminfo hoặc rocm-smi để đảm bảo hệ thống nhận diện được GPU.
Cách bật tăng tốc GPU AMD trong LM Studio
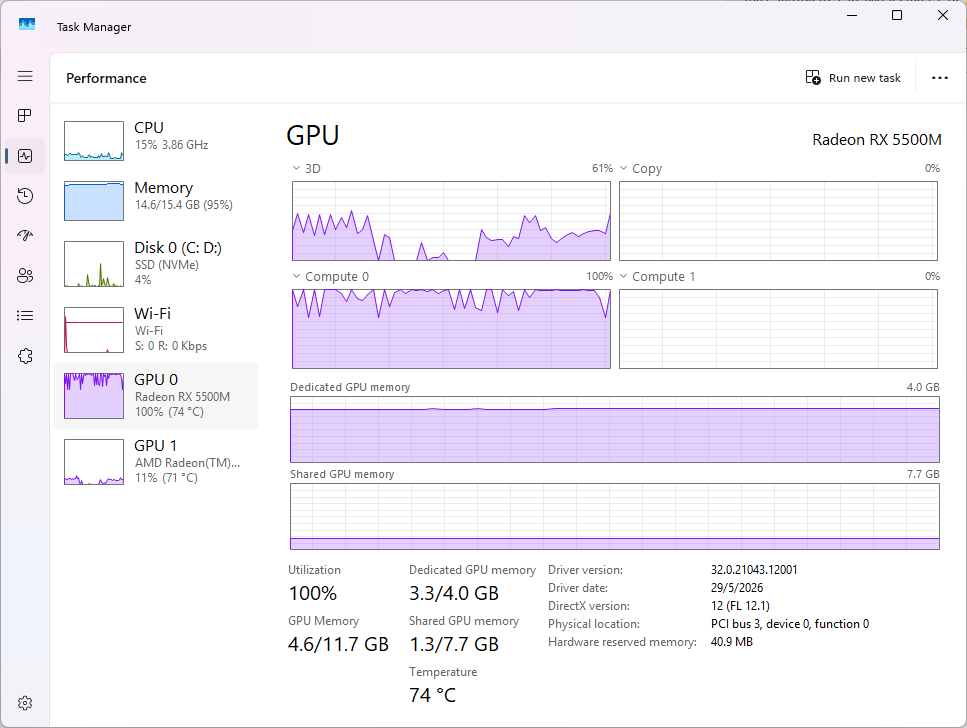
Đây là bước then chốt quyết định tốc độ suy luận. Sau khi mở LM Studio và tải một mô hình, bạn cần kiểm tra backend GPU:
- Mở tab My Models hoặc biểu tượng bánh răng bên cạnh tên mô hình đang tải.
- Tìm mục GPU Acceleration hoặc Hardware Acceleration.
- Chọn card AMD của bạn từ danh sách thiết bị. Nếu dùng Linux + ROCm, chọn backend ROCm/HIP. Nếu dùng Windows, chọn Vulkan hoặc DirectML.
- Điều chỉnh GPU Layers (số lớp offloading lên GPU). Đặt giá trị cao nhất có thể (ví dụ 99 hoặc max) để toàn bộ mô hình chạy trên VRAM, tránh fallback về CPU chậm chạp.
Nếu card AMD không xuất hiện trong danh sách, nguyên nhân thường là ROCm chưa được cài đúng cách (Linux) hoặc driver thiếu cập nhật (Windows). Với một số card không được hỗ trợ chính thức, bạn có thể thêm thủ công architecture ID (ví dụ gfx1103 cho AMD 780M) vào file backend-manifest.json trong thư mục cài đặt LM Studio, hoặc thay thế thư viện rocblas.dll bằng phiên bản tương thích từ cộng đồng.
Cách tải và chạy mô hình ngôn ngữ trong LM Studio
LM Studio tích hợp sẵn chợ mô hình từ Hugging Face, giúp bạn tìm kiếm dễ dàng:
- Chuyển sang tab Discover hoặc Search.
- Gõ tên mô hình bạn cần, ví dụ:
Qwen3 Coder,Llama 3.2,DeepSeek Coder,Mistral 7B. - Chọn phiên bản định dạng GGUF (định dạng chuẩn của LM Studio, tối ưu cho inference cục bộ).
- Chú ý đến mức quantization (Q4, Q5, Q8). Q4_K_M là lựa chọn cân bằng tốt nhất giữa chất lượng và dung lượng VRAM cho hầu hết mô hình 7B–13B.
- Nhấn Download và chờ hoàn tất.
Sau khi tải xong, chuyển sang tab Chat, chọn mô hình từ dropdown và bắt đầu trò chuyện. Nếu GPU được cấu hình đúng, bạn sẽ thấy phản hồi gần như tức thì với mô hình 7B, và khoảng 20–40 token/giây với card RX 7900 XT trở lên.
Nếu dùng để hỗ trợ code, nên chọn mô hình nào?
Với lập trình viên, các mô hình sau đây được cộng đồng đánh giá cao khi chạy local qua LM Studio:
- Qwen3 Coder (32B hoặc 14B): Hiểu sâu nhiều ngôn ngữ lập trình, hỗ trợ context dài, rất phù hợp refactor và giải thích code.
- DeepSeek Coder V2 (16B): Chuyên biệt cho coding, performance tốt trên phần cứng tầm trung.
- Llama 3.2 (3B/8B): Nhẹ, chạy mượt trên 8 GB VRAM, đủ dùng cho autocomplete và hỏi đáp đơn giản.
- Mistral 7B Instruct: Cân bằng tốt giữa tốc độ và khả năng reasoning, dễ tìm thấy phiên bản GGUF chất lượng cao.
Hãy nhớ rằng mô hình càng lớn thì cần càng nhiều VRAM. Với 16 GB VRAM, bạn có thể chạy Qwen3 14B ở Q4; với 24 GB VRAM, Qwen3 32B ở Q4 hoàn toàn khả thi.
Cách bật server API nội bộ để tích hợp với công cụ lập trình
Đây là tính năng biến LM Studio từ một ứng dụng chat thành nền tảng backend AI cho toàn bộ workflow của bạn. Server API của LM Studio tuân thủ chuẩn OpenAI, nghĩa là bất kỳ công cụ nào hỗ trợ custom base URL đều có thể kết nối.
Bật server trong giao diện đồ họa
- Tải và chọn mô hình bạn muốn phục vụ.
- Chuyển sang tab Local Server hoặc Server (biểu tượng máy chủ).
- Nhấn Start Server. Mặc định, server chạy tại
http://localhost:1234/v1. - Giữ LM Studio mở. Server sẽ chạy ngầm cho đến khi bạn tắt.
Tích hợp với Python hoặc ứng dụng bên thứ ba
Ví dụ kết nối bằng thư viện OpenAI trong Python:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:1234/v1",
api_key="lm-studio" # Không cần key thật khi chạy local
)
response = client.chat.completions.create(
model="qwen3-coder", # Tên mô hình đang load trong LM Studio
messages=[
{"role": "system", "content": "Bạn là trợ lý lập trình."},
{"role": "user", "content": "Viết hàm Python đọc file CSV bằng pandas"}
],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")Bạn cũng có thể dùng CLI lms để quản lý mô hình và server từ terminal:
curl -fsSL https://lmstudio.ai/cli/install.sh | bash
lms serve # Chạy server headless
lms chat # Chat trực tiếp từ terminal
lms get qwen3-coder # Tải mô hìnhNhờ đó, bạn có thể tích hợp LM Studio vào VS Code qua extension Continue.dev, vào Cursor IDE, hoặc bất kỳ công cụ nào cho phép thay đổi API endpoint. Toàn bộ quá trình xử lý diễn ra trên máy local, không có dữ liệu nào được gửi ra ngoài.
Mẹo tối ưu hiệu năng khi chạy LM Studio với GPU AMD
Để đạt tốc độ suy luận tốt nhất trên phần cứng AMD, áp dụng các mẹo sau:
- Luôn offloading tối đa lớp lên GPU: Trong settings, đẩy GPU Layers lên cao nhất. Nếu để 0 hoặc thấp, mô hình sẽ chạy trên CPU và chậm đi hàng chục lần.
- Chọn đúng quantization: Q4_K_M là điểm ngọt cho hầu hết use case. Q8 giữ chất lượng tốt hơn nhưng tốn gấp đôi VRAM. Tránh Q2 vì suy giảm chất lượng đáng kể.
- Giải phóng VRAM trước khi chạy: Tắt trình duyệt, game, hoặc ứng dụng đồ họa khác. Dùng
rocm-smi(Linux) hoặc Task Manager (Windows) để kiểm tra VRAM còn trống. - Cập nhật driver và LM Studio: Phiên bản mới thường cải thiện hỗ trợ ROCm và Vulkan. Kiểm tra tab Developer trong LM Studio để cài extension backend mới nhất.
- Dùng context length hợp lý: Đừng để max context quá cao nếu không cần. Context 4096 token đủ cho hầu hết tác vụ coding, trong khi 32K token sẽ ngốn VRAM gấp nhiều lần.
Nếu bạn gặp lỗi Out of Memory (OOM), hãy thử một trong các cách: giảm số lớp GPU, chọn mô hình nhỏ hơn, chuyển sang quantization thấp hơn, hoặc thêm flag --lowvram nếu dùng các backend hỗ trợ.
Xử lý sự cố thường gặp khi chạy LM Studio trên AMD
Dưới đây là các vấn đề phổ biến và cách khắc phục:
LM Studio không nhận diện được GPU AMD
Trên Linux, đảm bảo user đã được thêm vào nhóm render và video, sau đó khởi động lại. Chạy rocminfo để xác nhận ROCm hoạt động. Trên Windows, cập nhật driver AMD Adrenalin lên phiên bản mới nhất và thử chuyển sang backend Vulkan trong settings.
Mô hình load thành công nhưng chạy chậm như CPU
Kiểm tra log inference trong LM Studio. Nếu thấy dòng “offloaded 0/33 layers to GPU” nghĩa là không có lớp nào được đẩy lên GPU. Quay lại settings và tăng GPU Layers. Nếu vẫn không được, backend ROCm/Vulkan có thể chưa được kích hoạt — thử chuyển sang backend khác trong phần Runtime.
Lỗi HSA_OVERRIDE_GFX_VERSION trên card không được hỗ trợ
Thêm biến môi trường trước khi khởi động LM Studio. Ví dụ với RX 6600 (gfx1032):
export HSA_OVERRIDE_GFX_VERSION=10.3.0
./LM_Studio-*.AppImageHoặc thêm vào ~/.bashrc để áp dụng vĩnh viễn. Lưu ý rằng cách này không đảm bảo 100% ổn định cho mọi card.
Kết luận: AI cục bộ trên AMD đã sẵn sàng cho người dùng phổ thông
Vài năm trước, chạy LLM trên GPU AMD đồng nghĩa với hàng giờ vật lộn với driver, patch thủ công và hiệu năng thua xa NVIDIA. Năm 2026, mọi thứ đã thay đổi. LM Studio kết hợp với ROCm 6.x trên Linux hoặc Vulkan trên Windows mang đến trải nghiệm gần như plug-and-play cho chủ sở hữu card Radeon.
Với một chiếc RX 7800 XT 16 GB hoặc RX 7900 XTX 24 GB, bạn hoàn toàn có thể chạy mô hình 13B–32B ở tốc độ tương tác, phục vụ công việc coding, viết lách, phân tích tài liệu mà không tốn một xu cho API cloud. Dữ liệu riêng tư, phản hồi tức thì, và khả năng tùy chỉnh không giới hạn — đó là lý do ngày càng nhiều lập trình viên và chuyên gia chuyển sang local AI.
Hãy tải LM Studio, chọn một mô hình GGUF phù hợp với VRAM của bạn, bật GPU acceleration, và trải nghiệm sức mạnh AI ngay trên máy tính cá nhân. Nếu gặp khó khăn, cộng đồng LM Studio trên Discord và GitHub luôn sẵn sàng hỗ trợ.








Bình luận